| 题目名称 | 2402. [NOI 2016]优秀的拆分 |
|---|---|
| 输入输出 | excellent.in/out |
| 难度等级 | ★★★☆ |
| 时间限制 | 1500 ms (1.5 s) |
| 内存限制 | 512 MiB |
| 测试数据 | 20 |
| 题目来源 |
|
| 开放分组 | 全部用户 |
| 提交状态 | |
| 分类标签 | |
| 查看题解 | 分享题解 |
| 通过:40, 提交:96, 通过率:41.67% | ||||
|
|
100 | 0.171 s | 1.48 MiB | C++ |
|
|
100 | 0.178 s | 1.48 MiB | C++ |
|
|
100 | 0.279 s | 1.57 MiB | C++ |
|
|
100 | 0.310 s | 33.28 MiB | C++ |
|
|
100 | 0.314 s | 6.70 MiB | C++ |
|
|
100 | 0.324 s | 1.49 MiB | C++ |
|
|
100 | 0.358 s | 21.85 MiB | C++ |
|
|
100 | 0.358 s | 33.28 MiB | C++ |
|
|
100 | 0.368 s | 12.24 MiB | C++ |
|
|
100 | 0.371 s | 12.24 MiB | C++ |
| 关于 优秀的拆分 的近10条评论(全部评论) | ||||
|---|---|---|---|---|
|
注意:哈希值设19260817和31在unisgned long long下都会被卡
不要问我怎么知道的……最后改19491001才过…… 而且跑得很快……比100007快很多…… 心中有党,常数理想。 不过为了社会正能量还是建议双哈希。 | ||||
|
回复 @2018YaLi稳 :
我单哈希比双哈希慢= =
2018-01-26 17:46
7楼
| ||||
|
SAM搞LCP真是麻烦, 不过我并不会SA...
| ||||
|
被SA的清零坑2次
2017-04-29 15:55
5楼
| ||||
|
下标搞吐
2017-02-16 11:38
4楼
| ||||
|
暴力出奇迹,hash保平安。
双ha保正确,单ha刷榜1。 | ||||
|
注意SA清零的时候一定要清掉Wa和Wb,要不就真的Wa了
| ||||
|
我想要查看代码的权限@satoshi
| ||||
【问题描述】
如果一个字符串可以被拆分为 AABB 的形式,其中 A 和 B 是任意非空字符串, 则我们称该字符串的这种拆分是优秀的。
例如,对于字符串 aabaabaa,如果令 A = aab, B = a, 我们就找到了这个字符串拆分成 AABB 的一种方式。
一个字符串可能没有优秀的拆分,也可能存在不止一种优秀的拆分。 比如我们令 A = a, B = baa,也可以用 AABB 表示出上述字符串;但是,字符串abaabaa 就没有优秀的拆分。
现在给出一个长度为 n 的字符串 S,我们需要求出,在它所有子串的所有拆分方式中,优秀拆分的总个数。 这里的子串是指字符串中连续的一段。
以下事项需要注意:
1. 出现在不同位置的相同子串,我们认为是不同的子串,它们的优秀拆分均会被计入答案。
2. 在一个拆分中,允许出现 A = B。例如 cccc 存在拆分 A = B = c。
3. 字符串本身也是它的一个子串。
【输入格式】
每个输入文件包含多组数据。输入文件的第一行只有一个整数 T,表示数据 的组数。保证 1 ≤ T ≤ 10。
接下来 T 行,每行包含一个仅由英文小写字母构成的字符串 S,意义如题 所述。
【输出格式】
输出 T 行,每行包含一个整数,表示字符串 S 所有子串的所有拆分中, 总共有多少个是优秀的拆分。
【样例输入】
4 aabbbb cccccc aabaabaabaa bbaabaababaaba
【样例输出】
3 5 4 7
【样例说明】
我们用 S[i, j] 表示字符串 S 第 i 个字符到第 j 个字符的子串(从 1 开 始计数)。
第一组数据中,共有 3 个子串存在优秀的拆分:
S[1,4] = aabb,优秀的拆分为 A = a, B = b;
S[3,6] = bbbb,优秀的拆分为 A = b, B = b;
S[1,6] = aabbbb,优秀的拆分为 A = a, B = bb。
而剩下的子串不存在优秀的拆分,所以第一组数据的答案是 3。
第二组数据中, 有两类,总共 4 个子串存在优秀的拆分:
对于子串 S[1,4] = S[2,5] = S[3,6] = cccc, 它们优秀的拆分相同,均为 A = c, B = c,但由于这些子串位置不同,因此要计算 3 次;
对于子串 S[1,6] = cccccc,它优秀的拆分有 2 种: A = c, B = cc 和 A = cc, B = c,它们是相同子串的不同拆分,也都要计入答案。
所以第二组数据的答案是 3 + 2 = 5。
第三组数据中, S[1,8] 和 S[4,11] 各有 2 种优秀的拆分,其中 S[1,8] 是 问题描述中的例子,所以答案是 2 + 2 = 4。
第四组数据中, S[1,4], S[6,11], S[7,12], S[2,11], S[1,8] 各有 1 种优秀 的拆分, S[3,14] 有 2 种优秀的拆分,所以答案是 5 + 2 = 7。
【更多样例】
【样例 2 输入输出】
见目录下的 excellent/excellent2.in 与 excellent/excellent2.ans。
【样例 3 输入输出】
见目录下的 excellent/excellent3.in 与 excellent/excellent3.ans。
【子任务】
对于全部的测试点,保证 1 ≤ T ≤ 10。 以下对数据的限制均是对于单组输入数据而言的,也就是说同一个测试点下的 T 组数据均满足限制条件。
我们假定 n 为字符串 S 的长度,每个测试点的详细数据范围见下表:
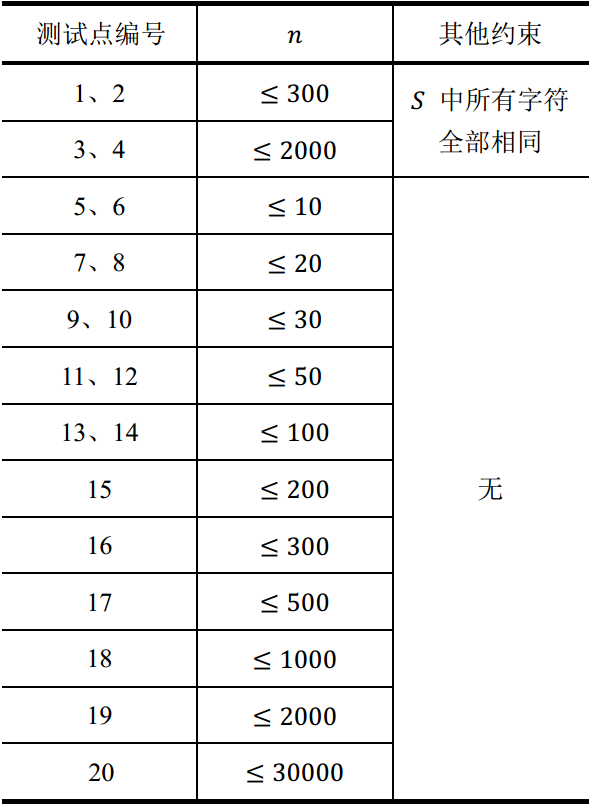
【来源】
NOI2016 Day1 T1