-
- 0/1分数规划
- 01BFS
- 01Trie
- 01背包
- 2-SAT
- A*
- ACM/ICPC
- AC自动机
- APIO
- BFS
- BFS序
- bitset 优化
- BSGS
- BYVoid
- CDQ分治
- COCI
- CodeChef
- Codeforces
- CTS论文相关
- DAG
- DFS
- DFS序
- DP套dp
- EZOI
- Fail树
- FFT
- FWT
- Gomory-Hu树
- HAOI
- HDU
- HEOI
- Hopcroft-karps算法
- hs的简单题
- HtBest
- HZOI
- IDA*
- IOI
- ISAP
- K-D Tree
- Keller系列
- KMP
- Kruskal 重构树
- K短路
- LCA
- LCP
- LCS
- LCT
- LIS
- Lucas定理
- Meet in the Middle算法
- NOI
- NOIP/CSP
- NP问题
- NTT
- POJ
- Polya 定理
- polya罐子模型
- RMQ
- SDOI
- SG函数
- Splay
- SPOJ
- ST表
- SYOI
- TopCoder
- Ural
- USACO
- UVa
- wqs 二分
- ZJOI
- 埃氏筛
- 半平面交
- 保序回归问题
- 背包类树形DP
- 背包问题
- 倍增法
- 表达式求值
- 表达式树
- 并查集
- 博弈论
- 插头DP
- 差分
- 差分约束
- 长链剖分
- 乘法逆元
- 乘法原理
- 次短路
- 次小生成树
- 带花树
- 带权并查集
- 带修莫队
- 单纯形
- 单调队列
- 单调栈
- 倒序处理
- 狄利克雷前缀和
- 笛卡尔树
- 递归
- 递推
- 点分治
- 点双连通分量
- 迭代加深搜索
- 动态规划
- 动态开点
- 动态树
- 动态图
- 杜教筛
- 堆
- 队列
- 对偶图
- 多项式求逆
- 多重背包
- 二叉树
- 二分答案
- 二分法
- 二分图
- 二分优化
- 二维背包
- 二维偏序
- 二维树状数组
- 二维线段树
- 二项式定理
- 反图
- 斐波那契数列
- 分层图
- 分块
- 分形
- 分治
- 分组背包
- 浮点运算
- 浮水法
- 复杂度分析
- 概率分析
- 概率与期望
- 高等数学
- 高精度
- 高精快速幂
- 高斯消元法
- 割点与桥
- 根号分治
- 构造
- 估价函数
- 滚动数组
- 哈夫曼树
- 合并类动态规划
- 黑白染色
- 后效性
- 后缀树
- 后缀数组
- 后缀自动机
- 划分树
- 换根
- 回溯法
- 回文
- 回文自动机
- 基本
- 基环树
- 基环树DP
- 集合幂级数
- 计数
- 计数类DP
- 计算几何
- 记忆化搜索
- 剪枝
- 交互式
- 结构体
- 结论
- 解异或方程组
- 局部搜索
- 矩阵乘法
- 矩阵快速幂
- 矩阵树定理
- 矩阵运算
- 决策单调性优化
- 卡特兰数
- 可持久化
- 可持久化Trie
- 可持久化平衡树
- 可持久化线段树
- 快速幂
- 扩展欧几里得算法
- 括号匹配
- 拉格朗日插值
- 勒让德定理
- 类背包
- 离散化
- 李超线段树
- 连通分量
- 连通性
- 链分治
- 轮廓线DP
- 洛谷
- 枚举
- 密码
- 模拟
- 模拟退火
- 模式匹配
- 模线性方程组
- 模型转换
- 莫比乌斯反演
- 莫队
- 莫队二次离线
- 母函数/生成函数
- 逆序对
- 欧几里得算法
- 欧拉定理及扩展
- 欧拉反演
- 欧拉函数
- 欧拉路径
- 欧拉筛法
- 排列组合
- 排序
- 平衡树
- 平面图
- 瓶颈生成树
- 启发式合并
- 前缀和
- 强连通分量
- 清北学堂
- 区间DP
- 群论
- 人工智能
- 容斥原理
- 三分法
- 三维莫队
- 三维偏序
- 散列
- 扫描线法
- 生物
- 树
- 树的直径
- 树的重心
- 树分块
- 树分治
- 树链剖分
- 树上差分
- 树套树
- 树形DP
- 树状数组
- 数据结构优化建图
- 数论
- 数位DP
- 数学
- 数值方法
- 双端队列
- 双连通分量
- 双向BFS
- 双向DFS
- 双向DP
- 双指针扫描法
- 思维
- 斯特林数
- 四叉树
- 四分树
- 搜索法
- 素数筛法
- 随机化
- 缩点
- 贪心
- 特判
- 替罪羊树
- 同余
- 凸包
- 凸轮
- 图的匹配
- 图论
- 拓扑排序
- 完全背包
- 网络流
- 位运算
- 文法分析
- 物理
- 稀疏表
- 仙人掌图
- 弦图
- 弦图和区间图
- 线段树
- 线段树分治
- 线段树合并
- 线性DP
- 线性规划
- 线性基
- 线性结构
- 线性空间
- 斜率优化
- 匈牙利算法
- 虚树
- 悬线法
- 压位
- 异或相关
- 映射
- 优先队列
- 有限状态自动机
- 圆方树
- 栈
- 找规律
- 折半递归
- 整体二分
- 整体分治
- 支配树
- 中国剩余定理
- 种子填充
- 重链剖分
- 主元素问题
- 状态压缩
- 状压DP
- 子集和变换
- 字典树/Trie
- 字符串
- 字符串哈希
- 字符串排序
- 自然数拆分问题
- 组合数学
- 最大公约数
- 最短路
- 最短路径树
- 最小表示法
- 最小割
- 最小割树
- 最小公倍数
- 最小生成树
- 最值子图
- 左偏树
- 题目
- 题解
- 记录
- 比赛(1)
- 页面
- 用户
- 评论

|
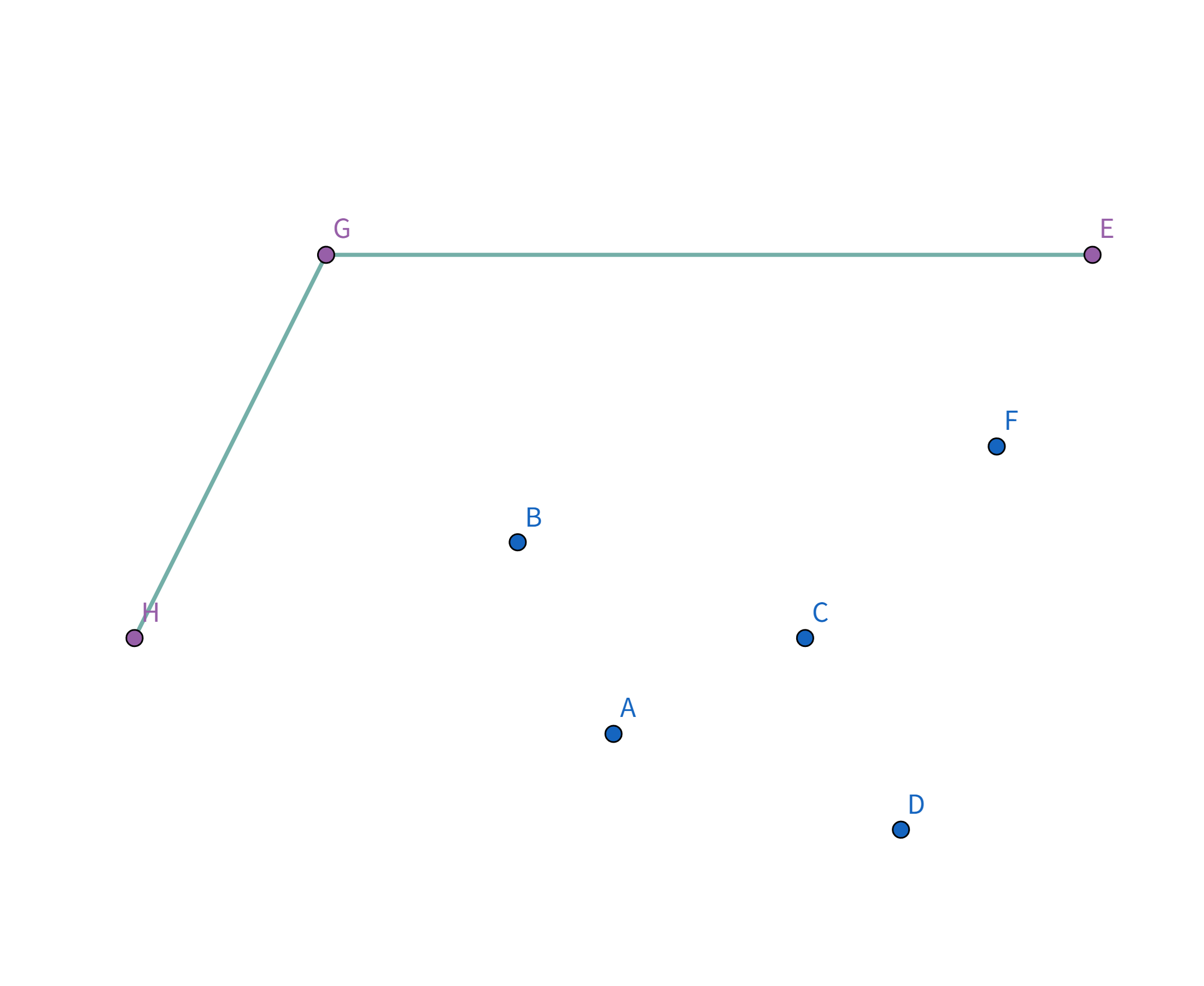
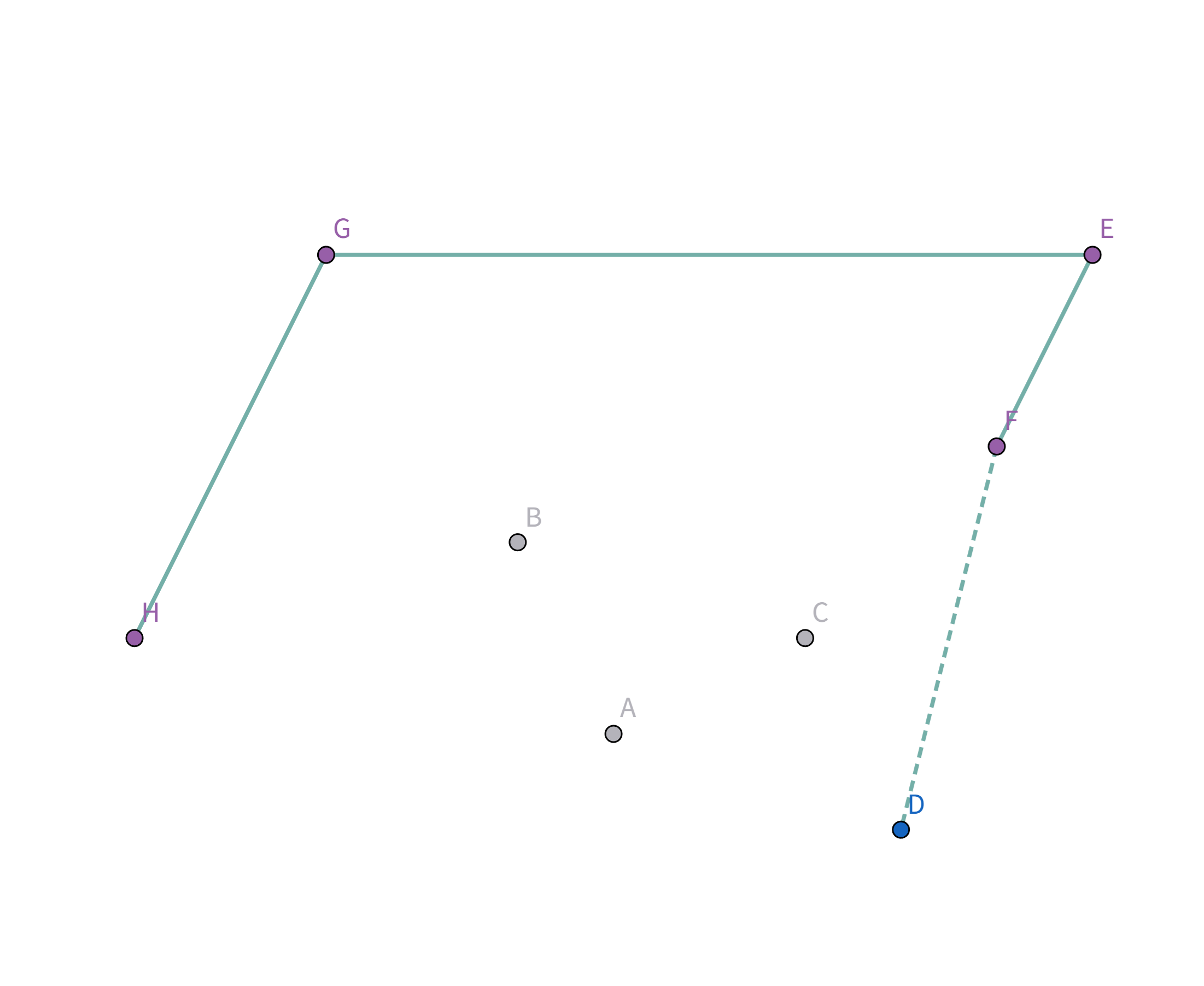
896. 圈奶牛 题解题意描述给定有 n 头奶牛,要把这些奶牛用栅栏围起来,栅栏的总长度即为花费,求花费的最小值。 题解例如有这么几头牛:
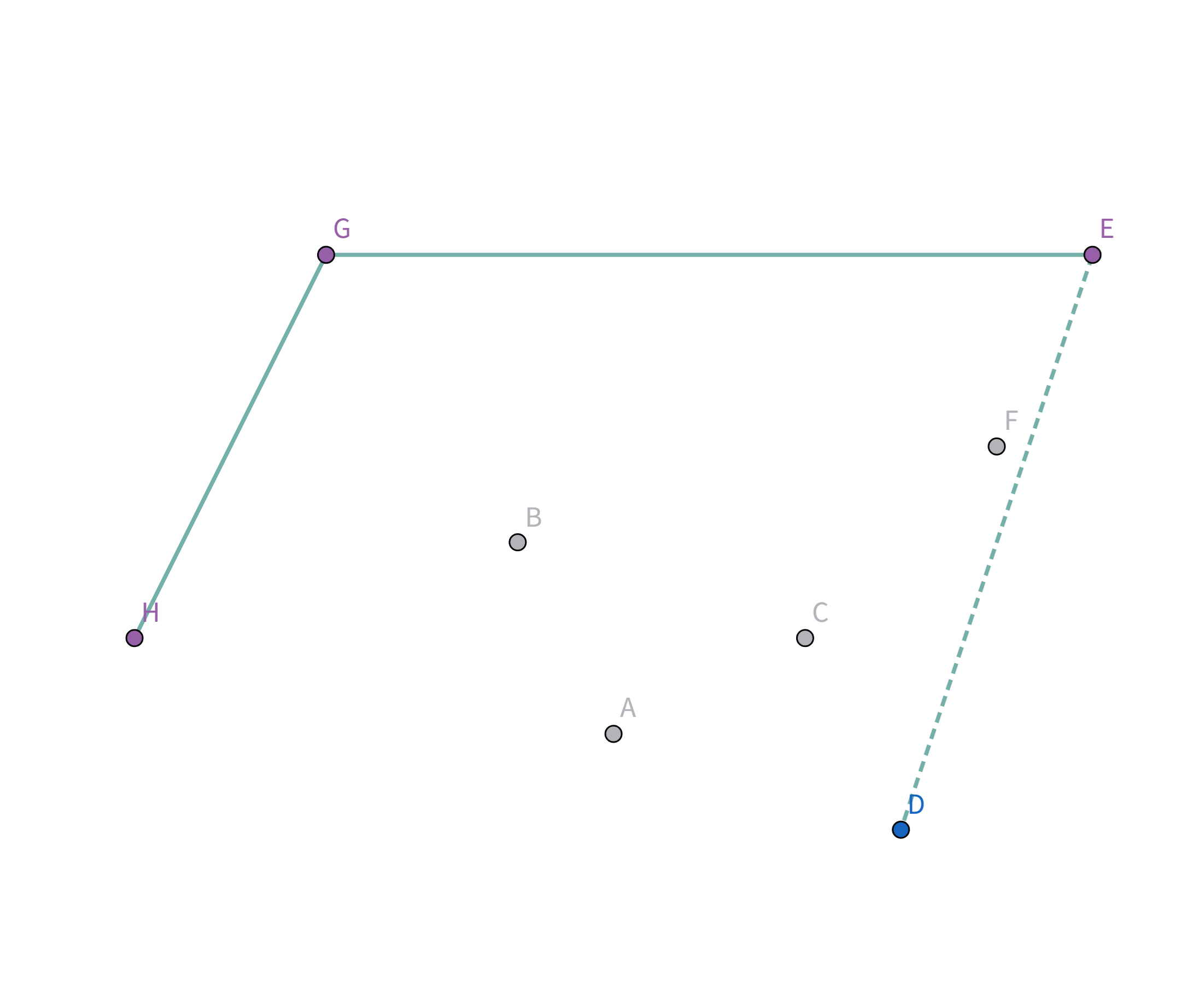
显然,一个想法是用一个圈把这些牛全部围起来:
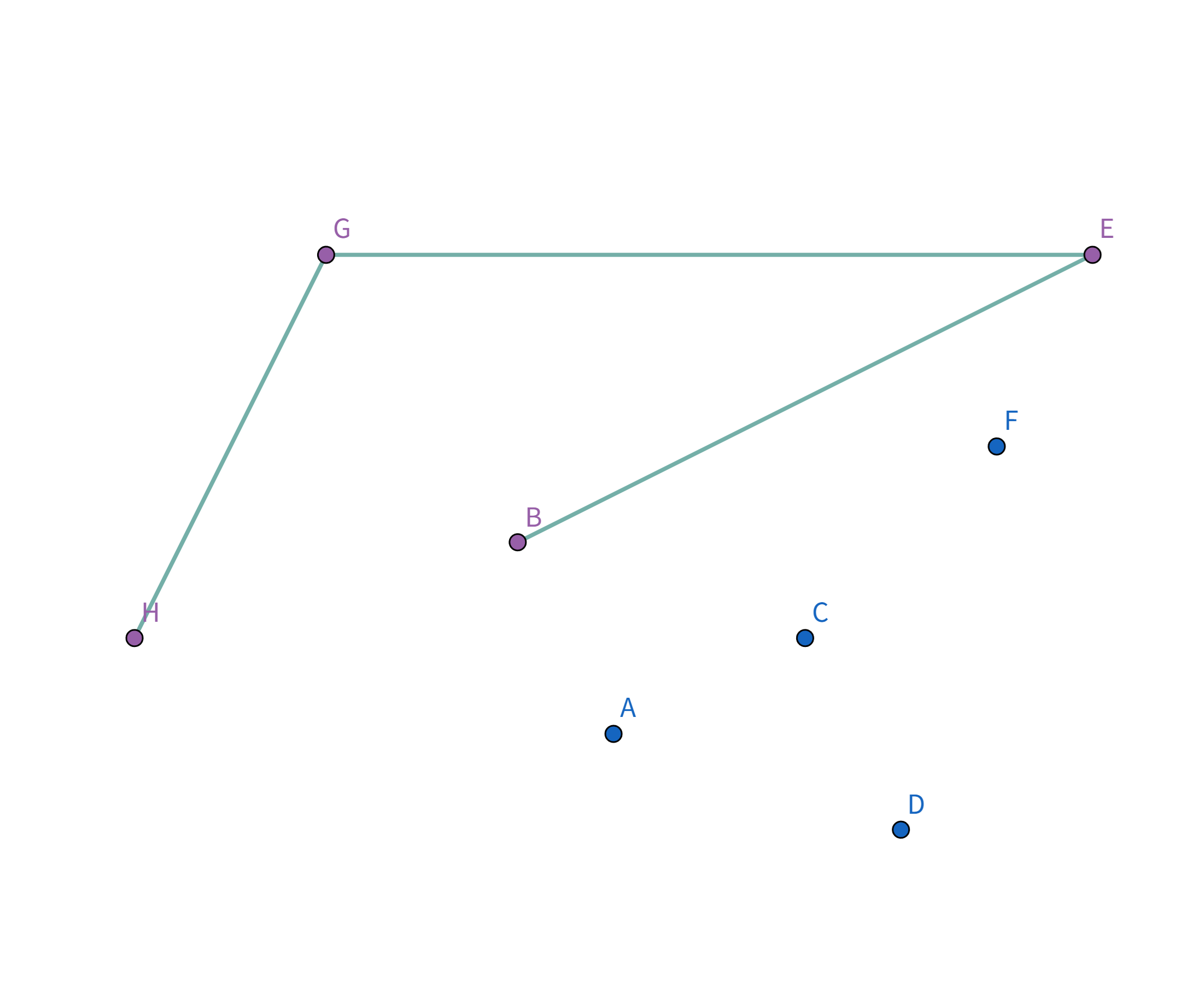
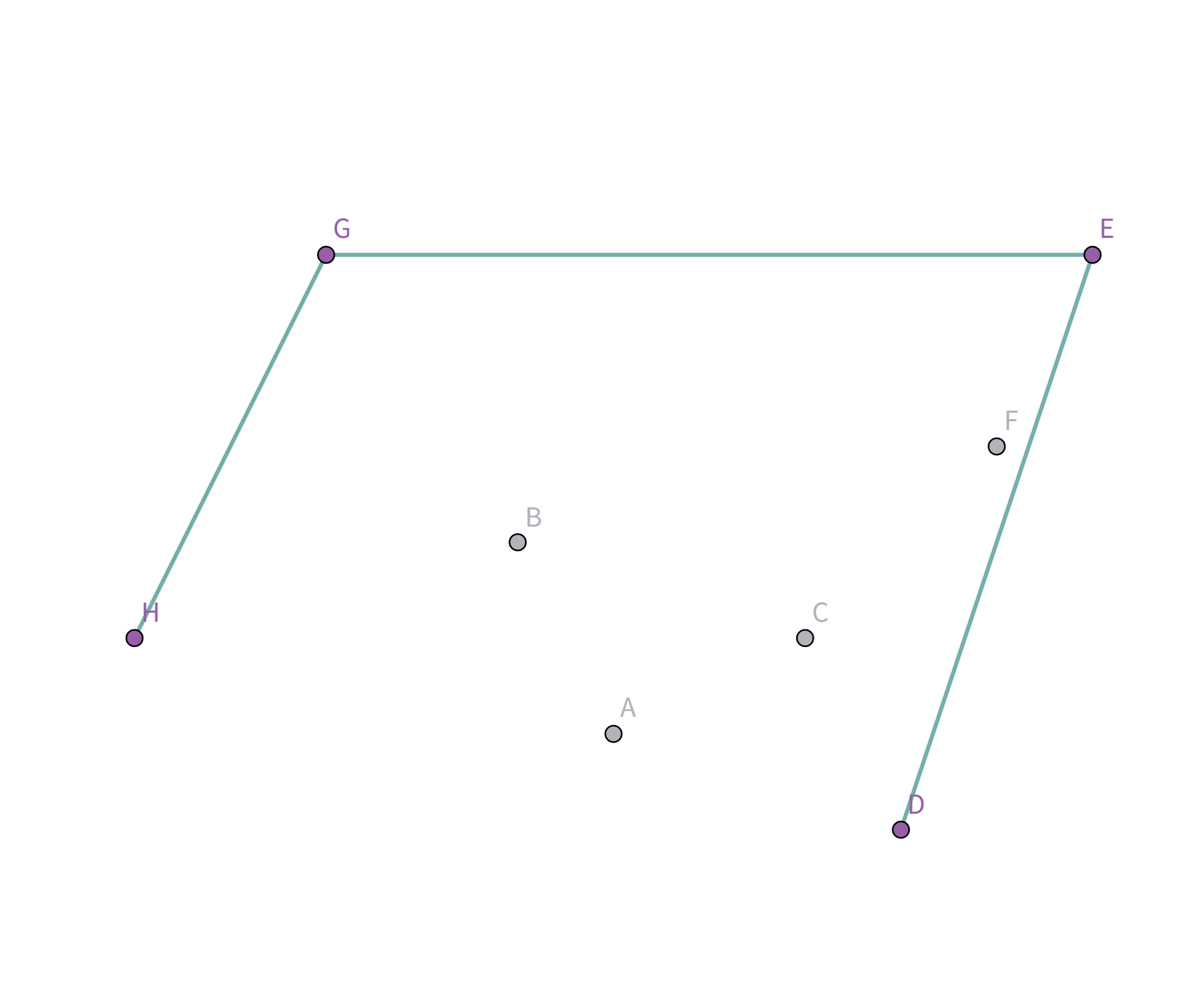
但是这样显然不是花费最小的,那我们就让这个椭圆一直缩小,直到和边缘上的点碰触就停止缩小:
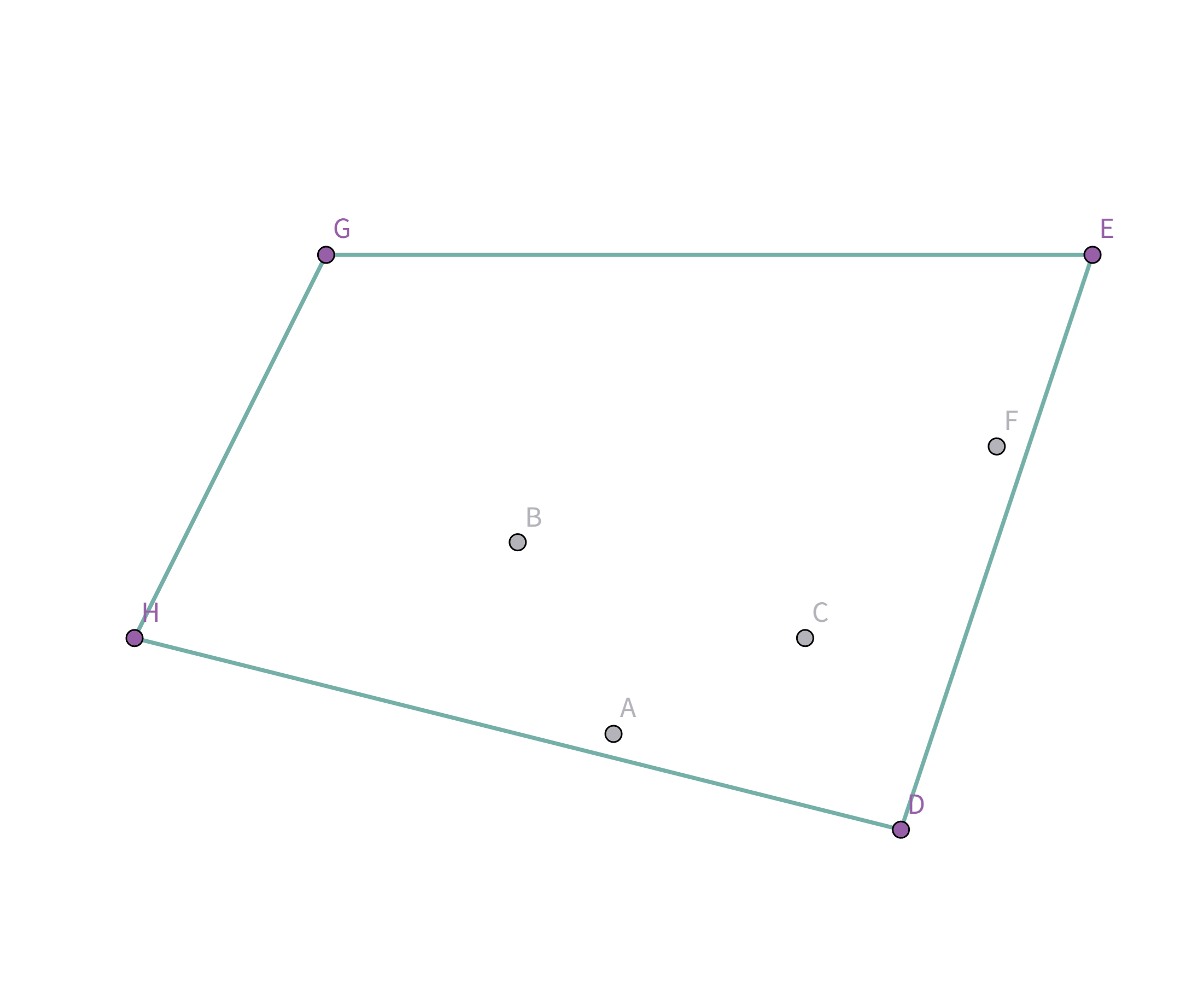
这样就是花费最小的啦! 如果再往里缩小的话,花费就会反而变长!
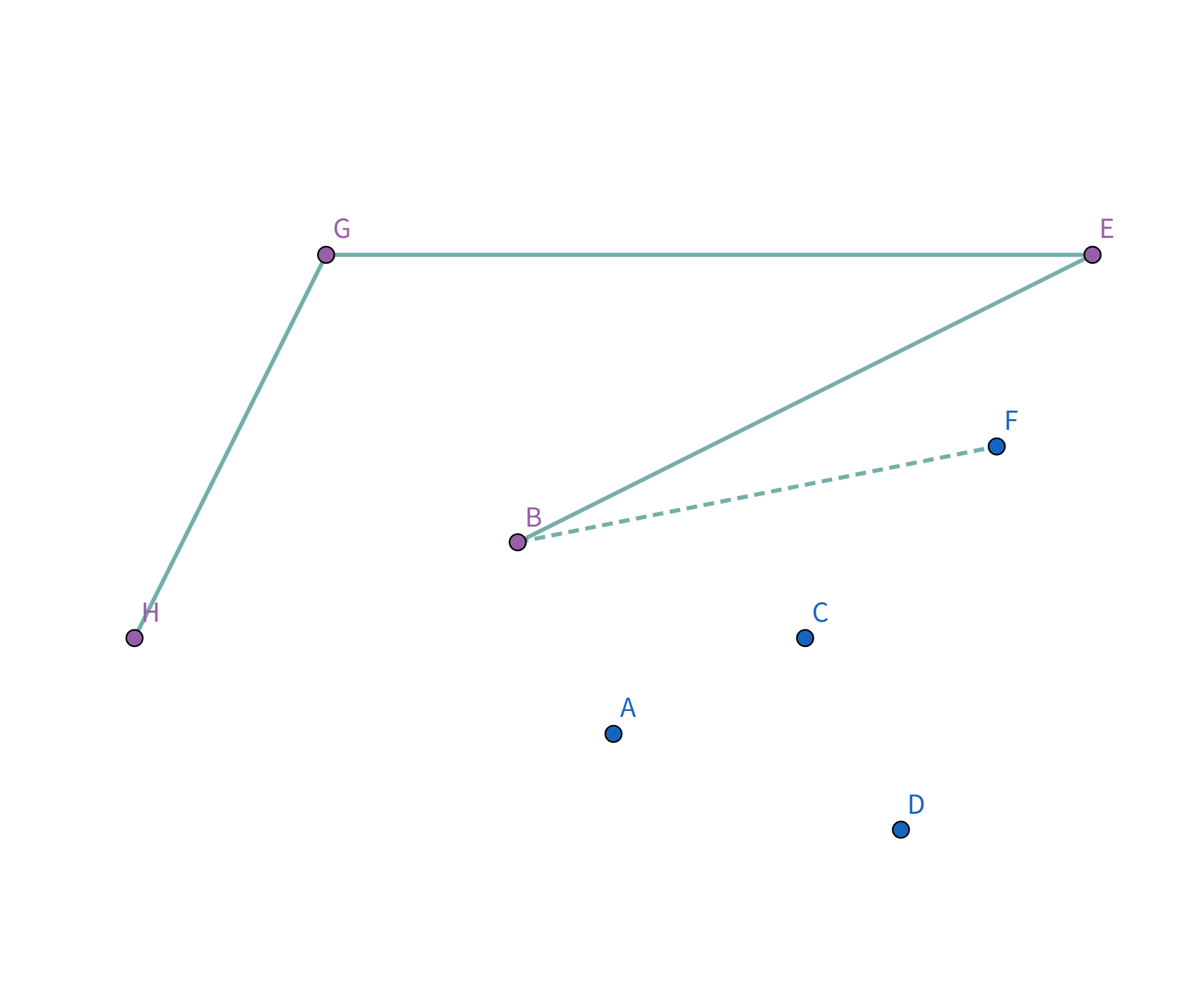
如图,在 $\triangle GHI$ 中,根据三边关系显然有 $GI + IH \gt GH$,所以 $GH$ 就是 $G$ 到 $H$ 花费最小的连接方式。
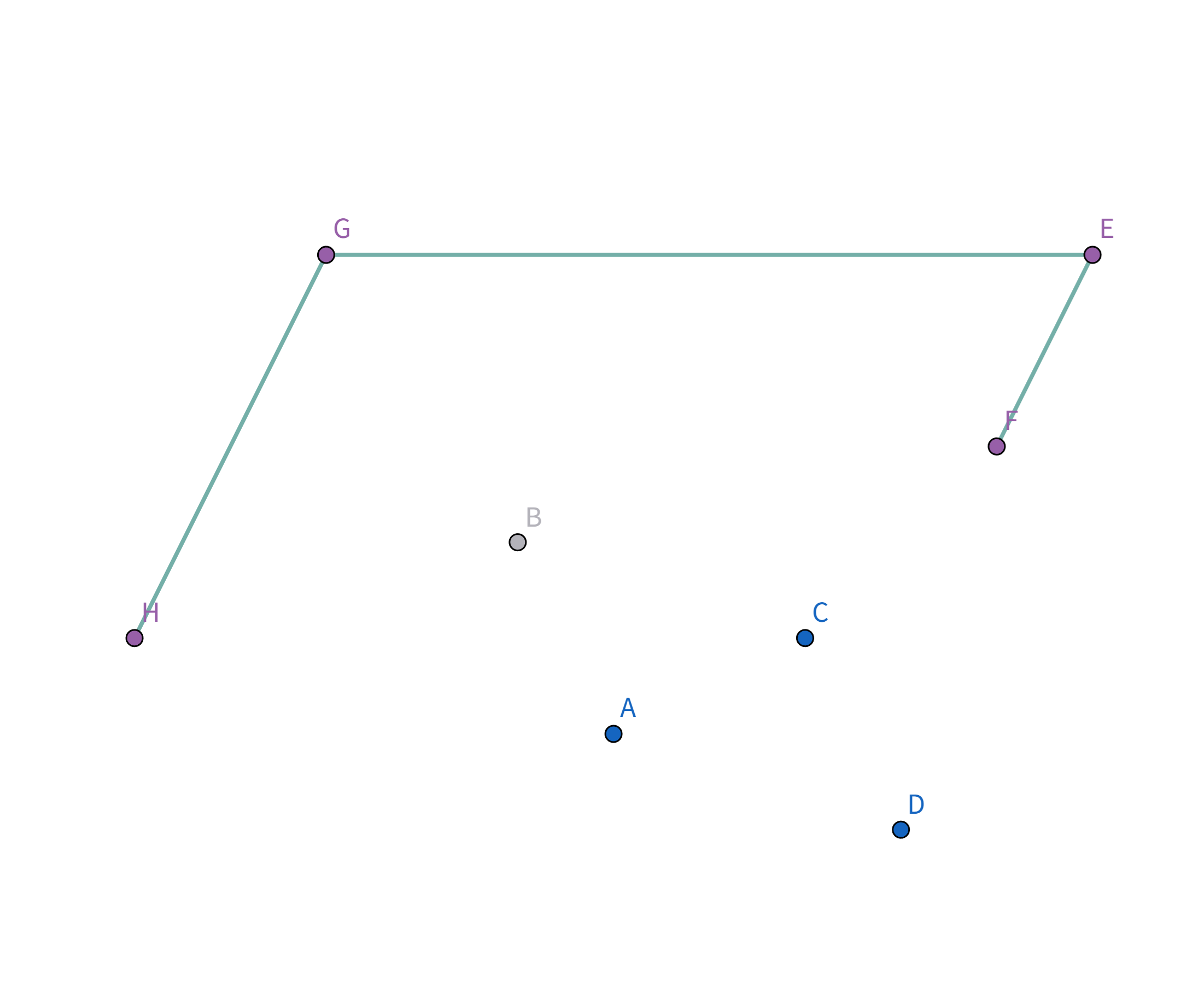
注意到这个连接方式的顶点连线的斜率是递减的 即: $$k_{HG} > k_{GE} > k_{ED} > k_{HD}$$ 那么,我们如何找到这个连接方式呢? 首先找到一个 $x$ 坐标或 $y$ 坐标最大/最小的点,例如图中的点 $H$、点 $G$、点 $E$、点 $D$。 我们以点 $H$ 为例,将这些点排序,按照其他点与点 $H$ 的连线的斜率降序排序(从小到大也可以,只不过实现略有不同):
struct NODE {
double x, y;
} node[MAXN];
double getk(NODE x, NODE y) {
return (x.y - y.y) / (x.x - y.x);
}
int main() {
... // 读入
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
}); // 先进行一个排序,按照 x 坐标为第一关键字升序
// y 坐标为第二关键字降序,也就是要把最左上角的点放到第一个
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return getk(x, node[1]) > getk(y, node[1]);
});
}
但是 [code](x.x - y.x)[/code] 容易等于零,除数等于零就错误了!那我们就将除法比较改成乘法叭 也就是: $$\frac{a_{1,y} - a_{2,y}}{a_{1,x} - a_{2.x}} \le \frac{b_{1,y} - b_{2,y}}{b_{1,x} - b_{2,x}} \\ \Downarrow \\ (a_{1,y} - a_{2,y})(b_{1,x} - b_{2,x}) \le (b_{1,y} - b_{2,y})(a_{1,x} - a_{2.x})$$
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int main() {
...
// 找到左上角的点
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
// 其余点按照与左上角的点连线的斜率降序排列
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return !check(x, node[1], y, node[1]);
});
...
}
接下来就是考虑怎么样把 $G,H,D,E$ 四个点选中啦! 我们用一个栈来维护选中的点。 首先点集是这样的:
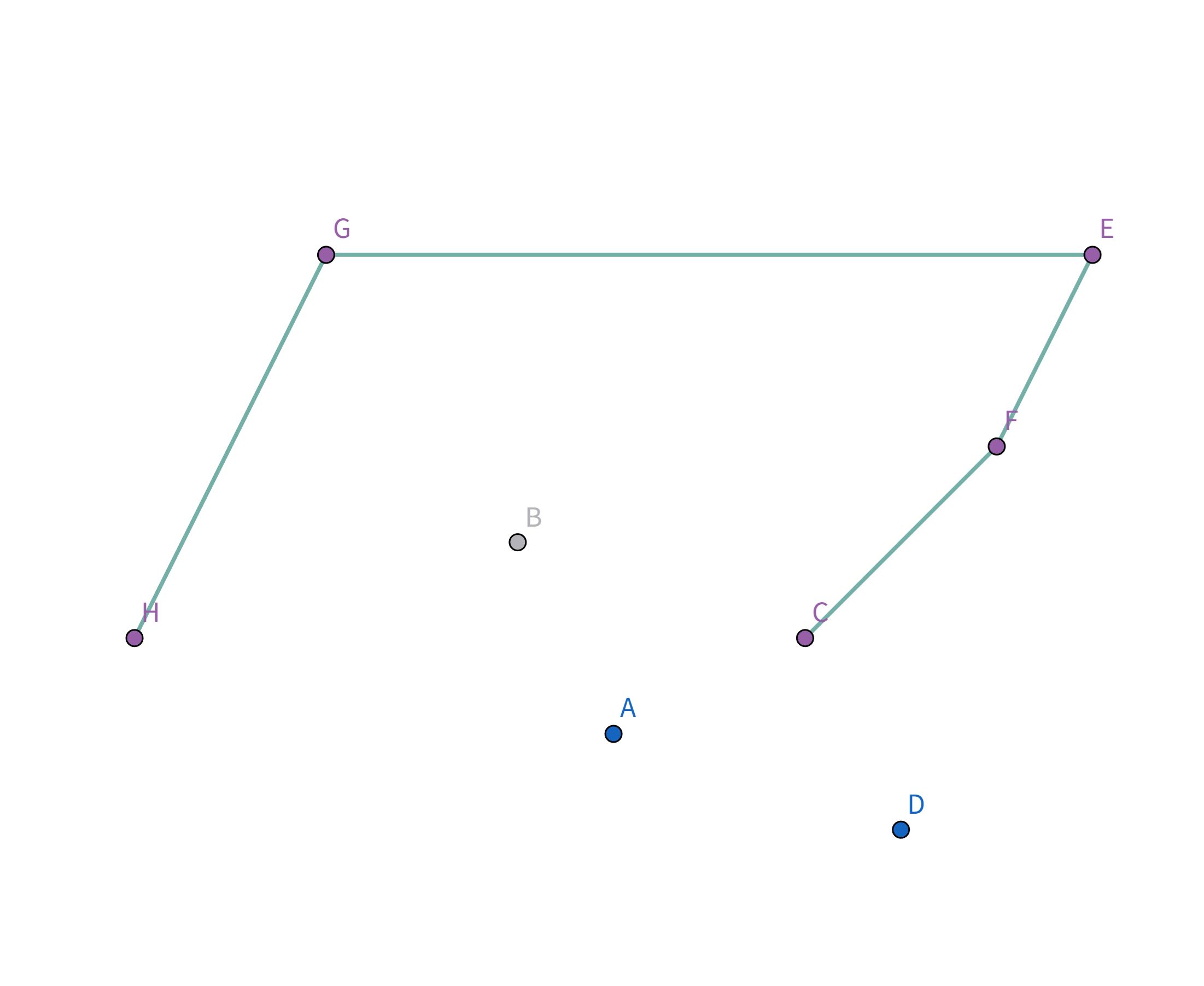
按照排序后的顺序取扫描,首先扫描到点 $H$,此时栈为空,直接把点 $H$ 加入栈:
接着扫描到点 $G$,站内只有一个元素,直接把点 $G$ 加入栈:
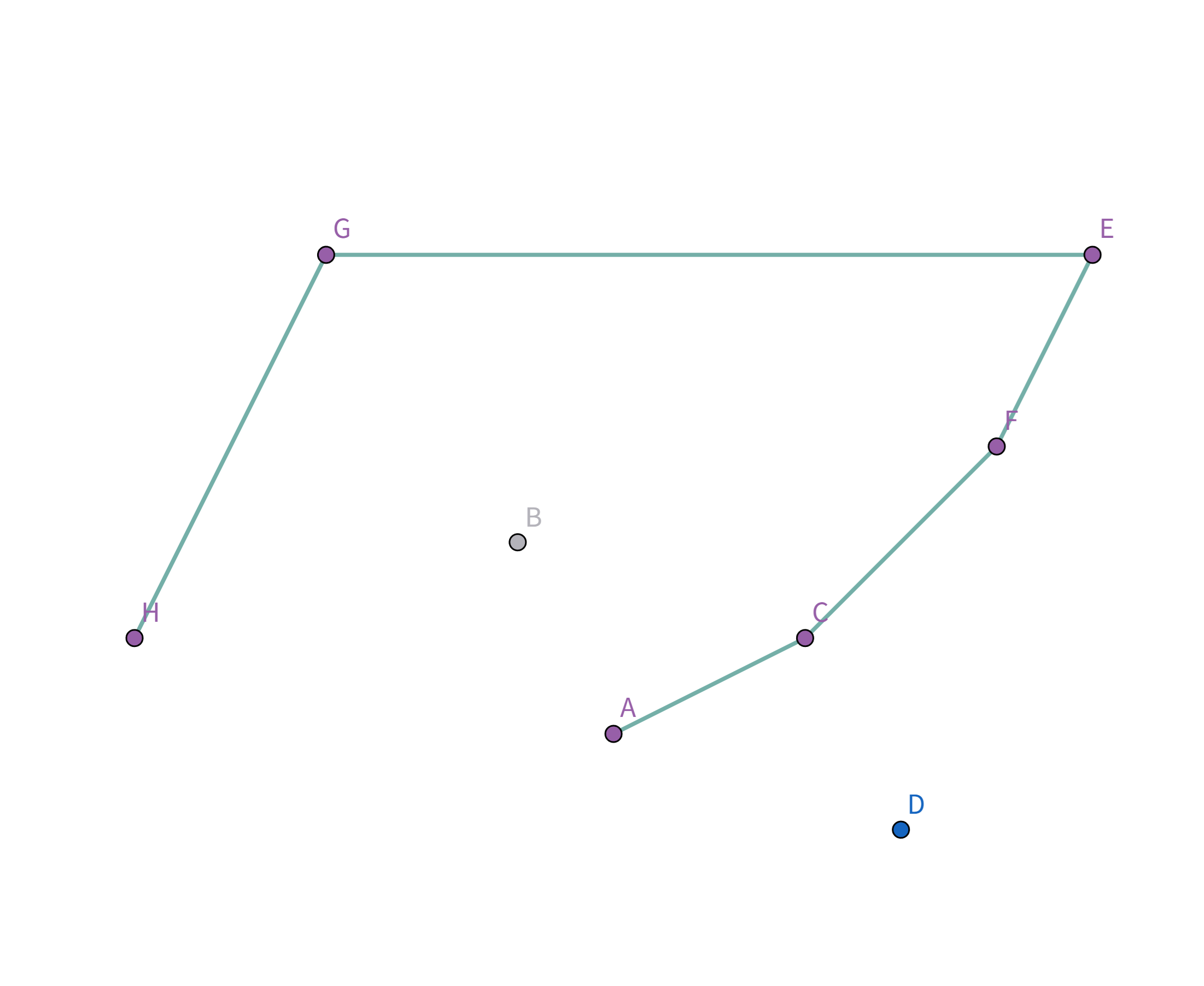
接着扫描到点 $E$,发现其与栈顶的点 $G$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
接着扫描到点 $B$,发现其与栈顶的点 $E$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
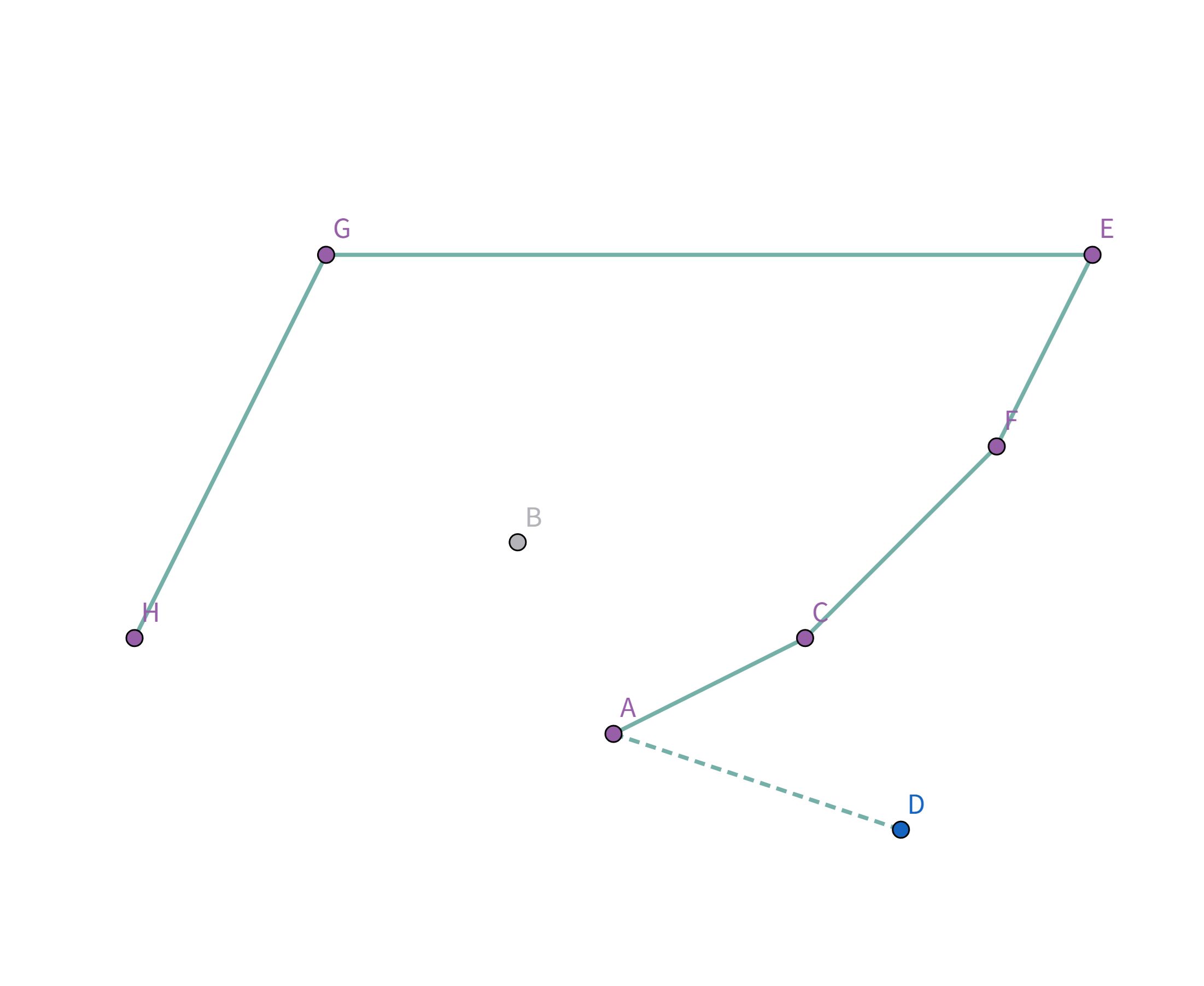
接着扫描到点 $F$!它与栈顶的点 $B$ 的连线斜率比之前大了!
所以把点 $B$ 踢出栈,重复检查点 $F$ 和点 $E$ 的连线是否符合要求。发现其与栈顶的点 $E$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
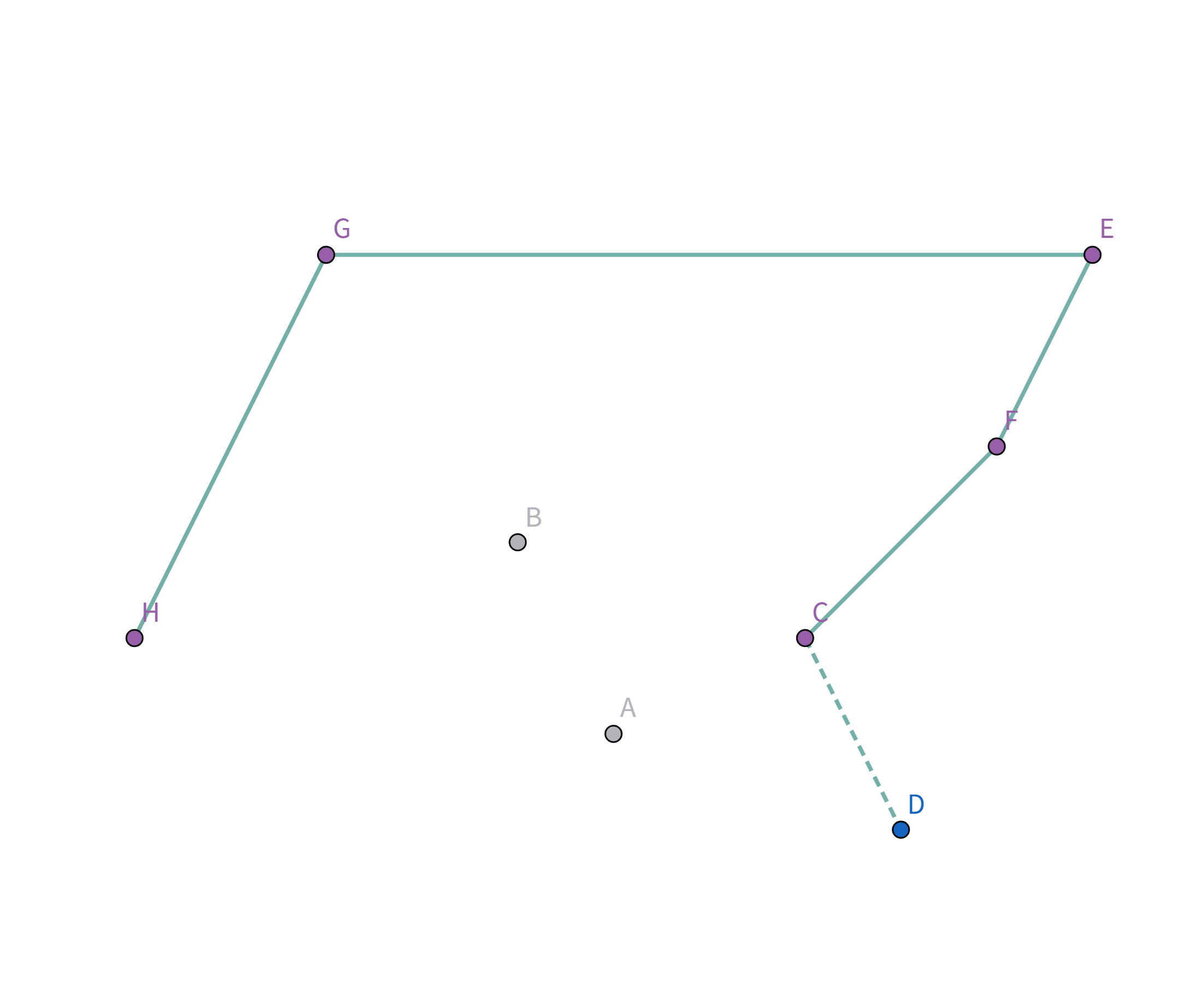
接着扫描到点 $C$,发现其与栈顶的点 $F$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
接着扫描到点 $A$,发现其与栈顶的点 $C$ 连线的斜率 与之前的所有连线的斜率 满足递减关系,直接入栈:
接着扫描到点 $D$!它与栈顶的点 $A$ 连线斜率比之前大!
所以把点 $A$ 踢出栈,重复检查点 $D$ 与栈顶点 $C$ 的连线,发现斜率仍然比之前大!
所以把点 $C$ 踢出栈,重复检查点 $D$ 与栈顶点 $F$ 的连线,发现斜率仍然比之前大!
所以把点 $F$ 踢出栈,重复检查点 $D$ 与栈顶点 $E$ 的连线:
终于满足条件了!点 $D$ 与栈顶点 $E$ 连线的斜率 与之前所有连线的斜率 满足递减关系,所以入栈:
所有的点都扫描完啦!所以把最后的点 $D$ 和第一个点 $H$ 连上就好啦!
和前面的图一模一样哦!这个过程模拟就好啦! (其实判断斜率是否满足要求就看这些线段是不是一直在右转就好嘿嘿) NODE sta[MAXN]; int top;
int main() {
...
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
...
}
此时,栈里面的元素就是要求的点集啦! 最后求花费不是难事: double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
double ans;
int main() {
...
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
...
}
最终代码:
#include <cstdio>
#include <algorithm>
#include <cmath>
using ::std::sort;
using ::std::pow;
using ::std::sqrt;
const int MAXN = 1e5 + 10;
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int n;
NODE sta[MAXN];
int top;
double ans;
int main() {
freopen("fc.in", "r", stdin);
freopen("fc.out", "w", stdout);
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
scanf("%lf %lf", &node[i].x, &node[i].y);
}
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
return !check(x, node[1], y, node[1]);
});
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
printf("%.2lf\n", ans);
return 0;
}
这个代码交到 COGS 上就能过啦!但是是错误的! HACK输入: 18 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0 11 0 12 0 13 0 14 0 15 0 16 0 17 0 18输出: 48.00正确答案: 34.00出现这个问题的原因是所有的点出现在了同一条竖直的线上,数据范围超出了阈值,[code]::std::sort[/code] 函数选择使用快速排序,那么这些点原来按 $y$ 坐标降序的顺序就无法被保证,而这些点传入 [code]check[/code] 函数总是会返回 [code]true[/code],因为 [code]b1.x - b2.x[/code] 和 [code]a1.x - a2.x[/code] 都为 0。最终导致花费计算过多。
解决的办法是排序的时候加上特判。对于在同一条水平的线上的点也用同样的方法就好啦!
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
if (x.x == node[1].x && y.x == node[1].x) return x.y > y.y; // 特判 x 坐标都一样
if (x.y == node[1].y && y.y == node[1].y) return x.x < y.x; // 特判 y 坐标都一样
return !check(x, node[1], y, node[1]);
});
最最终代码:
#include <cstdio>
#include <algorithm>
#include <cmath>
using ::std::sort;
using ::std::pow;
using ::std::sqrt;
const int MAXN = 1e5 + 10;
struct NODE {
double x, y;
} node[MAXN];
bool check(NODE a1, NODE a2, NODE b1, NODE b2) {
return (a1.y - a2.y) * (b1.x - b2.x) <= (b1.y - b2.y) * (a1.x - a2.x);
}
double dis(NODE x, NODE y) {
return sqrt(pow(x.x - y.x, 2) + pow(x.y - y.y, 2));
}
int n;
NODE sta[MAXN];
int top;
double ans;
int main() {
freopen("fc.in", "r", stdin);
freopen("fc.out", "w", stdout);
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
scanf("%lf %lf", &node[i].x, &node[i].y);
}
sort(node + 1, node + n + 1, [](NODE x, NODE y) {
if (x.x != y.x) return x.x < y.x;
return x.y > y.y;
});
sort(node + 2, node + n + 1, [](NODE x, NODE y) {
if (x.x == node[1].x && y.x == node[1].x) return x.y > y.y;
if (x.y == node[1].y && y.y == node[1].y) return x.x < y.x;
return !check(x, node[1], y, node[1]);
});
sta[++top] = node[1];
for (int i = 2; i <= n; ++i) {
while (top > 1 && !check(node[i], sta[top], sta[top], sta[top - 1])) top--;
sta[++top] = node[i];
}
for (int i = 2; i <= top; ++i) {
ans += dis(sta[i], sta[i - 1]);
}
ans += dis(sta[top], sta[1]);
printf("%.2lf\n", ans);
return 0;
}
时间复杂度:$O(n \log{n} + n)$,瓶颈在排序。
2025-10-05 08:58:19
|